1. typedef for array of pointers:
https://stackoverflow.com/questions/16179073/accessing-elements-of-typedefed-array-of-pointers
believe what you're looking for is the following...
#define N 128
#define ELEMENTS 10
typedef int* arrayOfNPointers[N];
arrayOfNPointers myPtrs = { 0 };
int i;
for (i=0; i<N; i++) {
myPtrs[i] = malloc(sizeof( int ) * ELEMENTS);
}
You want arrayOfPointer to be an array of N pointers to ELEMENTS integers. Also, when you malloc() the space for your integers, you need to multiply the number of ELEMENTS by the size of an integer. As it is, the space you're allocating is too small to hold the data you're trying to store in it.
Your typedef declared arrayOfPointer as a pointer to an array of N integers. Remember to use the right-left reading rule to understand what you are declaring a variable/type to be. Because you had (*arrayOfPointer) in parens there was nothing to the right and a pointer to the left, so arrayOfPointer is a pointer TO [N] (right) int (left). Not what you intended.
2. structure padding:
https://www.geeksforgeeks.org/structure-member-alignment-padding-and-data-packing/
https://fresh2refresh.com/c-programming/c-structure-padding/
3. preprocessor macros:
https://renenyffenegger.ch/notes/development/languages/C-C-plus-plus/preprocessor/macros/index
https://gcc.gnu.org/onlinedocs/cpp/Concatenation.html
https://gcc.gnu.org/onlinedocs/cpp/Macros.html#Macros
# operator:
// CPP program to illustrate (#) operator
#include <stdio.h>
#define mkstr(s) #s
int main(void)
{
printf(mkstr(geeksforgeeks));
return 0;
}
4. fseek and ftell:
ftell() and fseek()
Last Updated: 2021-02-28
- A file position stored by ftell()
- A calculated record number (
SEEK_SET) - A position relative to the current position (
SEEK_CUR) - A position relative to the end of the file (
SEEK_END)
seek() is used to move file pointer associated with a given file to a specific position.
Syntax:
int fseek(FILE *pointer, long int offset, int position) pointer: pointer to a FILE object that identifies the stream. offset: number of bytes to offset from position position: position from where offset is added. returns: zero if successful, or else it returns a non-zero value
position defines the point with respect to which the file pointer needs to be moved. It has three values:
SEEK_END : It denotes end of the file.
SEEK_SET : It denotes starting of the file.
SEEK_CUR : It denotes file pointer’s current position.
random links:
1. implment tail - https://codereview.stackexchange.com/questions/43142/tail-implementation-in-c#:~:text=Write%20the%20program%20tail%20%2C%20which,input%20or%20the%20value%20n%20.
2. https://www.geeksforgeeks.org/implement-your-own-tail-read-last-n-lines-of-a-huge-file/
PC:Sockets
https://users.cs.cf.ac.uk/dave/C/node28.html
https://www.tutorialspoint.com/interprocess-communication-with-sockets
https://opensource.com/article/19/4/interprocess-communication-linux-networking
Sockets provide point-to-point, two-way communication between two processes. Sockets are very versatile and are a basic component of interprocess and intersystem communication. A socket is an endpoint of communication to which a name can be bound. It has a type and one or more associated processes.
Sockets exist in communication domains. A socket domain is an abstraction that provides an addressing structure and a set of protocols. Sockets connect only with sockets in the same domain. Twenty three socket domains are identified (see <sys/socket.h>), of which only the UNIX and Internet domains are normally used Solaris 2.x Sockets can be used to communicate between processes on a single system, like other forms of IPC.
The UNIX domain provides a socket address space on a single system. UNIX domain sockets are named with UNIX paths. Sockets can also be used to communicate between processes on different systems. The socket address space between connected systems is called the Internet domain.
Internet domain communication uses the TCP/IP internet protocol suite.
Socket types define the communication properties visible to the application. Processes communicate only between sockets of the same type. There are five types of socket.
- A stream socket
- -- provides two-way, sequenced, reliable, and unduplicated flow of data with no record boundaries. A stream operates much like a telephone conversation. The socket type is SOCK_STREAM, which, in the Internet domain, uses Transmission Control Protocol (TCP).
- A datagram socket
- -- supports a two-way flow of messages. A on a datagram socket may receive messages in a different order from the sequence in which the messages were sent. Record boundaries in the data are preserved. Datagram sockets operate much like passing letters back and forth in the mail. The socket type is SOCK_DGRAM, which, in the Internet domain, uses User Datagram Protocol (UDP).
- A sequential packet socket
- -- provides a two-way, sequenced, reliable, connection, for datagrams of a fixed maximum length. The socket type is SOCK_SEQPACKET. No protocol for this type has been implemented for any protocol family.
- A raw socket
- provides access to the underlying communication protocols.
These sockets are usually datagram oriented, but their exact characteristics depend on the interface provided by the protocol.
Socket Creation and Naming
int socket(int domain, int type, int protocol) is called to create a socket in the specified domain and of the specified type. If a protocol is not specified, the system defaults to a protocol that supports the specified socket type. The socket handle (a descriptor) is returned. A remote process has no way to identify a socket until an address is bound to it. Communicating processes connect through addresses. In the UNIX domain, a connection is usually composed of one or two path names. In the Internet domain, a connection is composed of local and remote addresses and local and remote ports. In most domains, connections must be unique.
int bind(int s, const struct sockaddr *name, int namelen) is called to bind a path or internet address to a socket. There are three different ways to call bind(), depending on the domain of the socket.
- For UNIX domain sockets with paths containing 14, or fewer characters, you can:
#include <sys/socket.h> ... bind (sd, (struct sockaddr *) &addr, length);
- If the path of a UNIX domain socket requires more characters, use:
#include <sys/un.h> ... bind (sd, (struct sockaddr_un *) &addr, length);
- For Internet domain sockets, use
#include <netinet/in.h> ... bind (sd, (struct sockaddr_in *) &addr, length);
In the UNIX domain, binding a name creates a named socket in the file system. Use unlink() or rm () to remove the socket.
Connecting Stream Sockets
Connecting sockets is usually not symmetric. One process usually acts as a server and the other process is the client. The server binds its socket to a previously agreed path or address. It then blocks on the socket. For a SOCK_STREAM socket, the server calls int listen(int s, int backlog) , which specifies how many connection requests can be queued. A client initiates a connection to the server's socket by a call to int connect(int s, struct sockaddr *name, int namelen) . A UNIX domain call is like this:
struct sockaddr_un server; ... connect (sd, (struct sockaddr_un *)&server, length);
while an Internet domain call would be:
struct sockaddr_in; ... connect (sd, (struct sockaddr_in *)&server, length);
If the client's socket is unbound at the time of the connect call, the system automatically selects and binds a name to the socket. For a SOCK_STREAM socket, the server calls accept(3N) to complete the connection.
int accept(int s, struct sockaddr *addr, int *addrlen) returns a new socket descriptor which is valid only for the particular connection. A server can have multiple SOCK_STREAM connections active at one time.
Stream Data Transfer and Closing
Several functions to send and receive data from a SOCK_STREAM socket. These are write(), read(), int send(int s, const char *msg, int len, int flags), and int recv(int s, char *buf, int len, int flags). send() and recv() are very similar to read() and write(), but have some additional operational flags.
The flags parameter is formed from the bitwise OR of zero or more of the following:
- MSG_OOB
- -- Send "out-of-band" data on sockets that support this notion. The underlying protocol must also support "out-of-band" data. Only SOCK_STREAM sockets created in the AF_INET address family support out-of-band data.
- MSG_DONTROUTE
- -- The SO_DONTROUTE option is turned on for the duration of the operation. It is used only by diagnostic or routing pro- grams.
- MSG_PEEK
- -- "Peek" at the data present on the socket; the data is returned, but not consumed, so that a subsequent receive operation will see the same data.
A SOCK_STREAM socket is discarded by calling close().
Datagram sockets
A datagram socket does not require that a connection be established. Each message carries the destination address. If a particular local address is needed, a call to bind() must precede any data transfer. Data is sent through calls to sendto() or sendmsg(). The sendto() call is like a send() call with the destination address also specified. To receive datagram socket messages, call recvfrom() or recvmsg(). While recv() requires one buffer for the arriving data, recvfrom() requires two buffers, one for the incoming message and another to receive the source address.
Datagram sockets can also use connect() to connect the socket to a specified destination socket. When this is done, send() and recv() are used to send and receive data.
accept() and listen() are not used with datagram sockets.
Socket Options
Sockets have a number of options that can be fetched with getsockopt() and set with setsockopt(). These functions can be used at the native socket level (level = SOL_SOCKET), in which case the socket option name must be specified. To manipulate options at any other level the protocol number of the desired protocol controlling the option of interest must be specified (see getprotoent() in getprotobyname()).
Example Socket Programs:socket_server.c,socket_client
These two programs show how you can establish a socket connection using the above functions.
socket_server.c
#include <sys/types.h>
#include <sys/socket.h>
#include <sys/un.h>
#include <stdio.h>
#define NSTRS 3 /* no. of strings */
#define ADDRESS "mysocket" /* addr to connect */
/*
* Strings we send to the client.
*/
char *strs[NSTRS] = {
"This is the first string from the server.\n",
"This is the second string from the server.\n",
"This is the third string from the server.\n"
};
main()
{
char c;
FILE *fp;
int fromlen;
register int i, s, ns, len;
struct sockaddr_un saun, fsaun;
/*
* Get a socket to work with. This socket will
* be in the UNIX domain, and will be a
* stream socket.
*/
if ((s = socket(AF_UNIX, SOCK_STREAM, 0)) < 0) {
perror("server: socket");
exit(1);
}
/*
* Create the address we will be binding to.
*/
saun.sun_family = AF_UNIX;
strcpy(saun.sun_path, ADDRESS);
/*
* Try to bind the address to the socket. We
* unlink the name first so that the bind won't
* fail.
*
* The third argument indicates the "length" of
* the structure, not just the length of the
* socket name.
*/
unlink(ADDRESS);
len = sizeof(saun.sun_family) + strlen(saun.sun_path);
if (bind(s, &saun, len) < 0) {
perror("server: bind");
exit(1);
}
/*
* Listen on the socket.
*/
if (listen(s, 5) < 0) {
perror("server: listen");
exit(1);
}
/*
* Accept connections. When we accept one, ns
* will be connected to the client. fsaun will
* contain the address of the client.
*/
if ((ns = accept(s, &fsaun, &fromlen)) < 0) {
perror("server: accept");
exit(1);
}
/*
* We'll use stdio for reading the socket.
*/
fp = fdopen(ns, "r");
/*
* First we send some strings to the client.
*/
for (i = 0; i < NSTRS; i++)
send(ns, strs[i], strlen(strs[i]), 0);
/*
* Then we read some strings from the client and
* print them out.
*/
for (i = 0; i < NSTRS; i++) {
while ((c = fgetc(fp)) != EOF) {
putchar(c);
if (c == '\n')
break;
}
}
/*
* We can simply use close() to terminate the
* connection, since we're done with both sides.
*/
close(s);
exit(0);
}
socket_client.c
#include <sys/types.h>
#include <sys/socket.h>
#include <sys/un.h>
#include <stdio.h>
#define NSTRS 3 /* no. of strings */
#define ADDRESS "mysocket" /* addr to connect */
/*
* Strings we send to the server.
*/
char *strs[NSTRS] = {
"This is the first string from the client.\n",
"This is the second string from the client.\n",
"This is the third string from the client.\n"
};
main()
{
char c;
FILE *fp;
register int i, s, len;
struct sockaddr_un saun;
/*
* Get a socket to work with. This socket will
* be in the UNIX domain, and will be a
* stream socket.
*/
if ((s = socket(AF_UNIX, SOCK_STREAM, 0)) < 0) {
perror("client: socket");
exit(1);
}
/*
* Create the address we will be connecting to.
*/
saun.sun_family = AF_UNIX;
strcpy(saun.sun_path, ADDRESS);
/*
* Try to connect to the address. For this to
* succeed, the server must already have bound
* this address, and must have issued a listen()
* request.
*
* The third argument indicates the "length" of
* the structure, not just the length of the
* socket name.
*/
len = sizeof(saun.sun_family) + strlen(saun.sun_path);
if (connect(s, &saun, len) < 0) {
perror("client: connect");
exit(1);
}
/*
* We'll use stdio for reading
* the socket.
*/
fp = fdopen(s, "r");
/*
* First we read some strings from the server
* and print them out.
*/
for (i = 0; i < NSTRS; i++) {
while ((c = fgetc(fp)) != EOF) {
putchar(c);
if (c == '\n')
break;
}
}
/*
* Now we send some strings to the server.
*/
for (i = 0; i < NSTRS; i++)
send(s, strs[i], strlen(strs[i]), 0);
/*
* We can simply use close() to terminate the
* connection, since we're done with both sides.
*/
close(s);
exit(0);
}6. Signalshttps://opensource.com/article/19/4/interprocess-communication-linux-networkinghttps://users.cs.cf.ac.uk/dave/C/node24.html#SECTION002400000000000000000https://www.networkworld.com/article/3211296/unix-dealing-with-signals.htmlhttp://www.cs.kent.edu/~ruttan/sysprog/lectures/signals.htmlhttps://www-uxsup.csx.cam.ac.uk/courses/moved.Building/signals.pdfA signal interrupts an executing program and, in this sense, communicates with it. Most signals can be either ignored (blocked) or handled (through designated code), with SIGSTOP (pause) and SIGKILL (terminate immediately) as the two notable exceptions. Symbolic constants such as SIGKILL have integer values, in this case, 9.
Signals can arise in user interaction. For example, a user hits Ctrl+C from the command line to terminate a program started from the command-line; Ctrl+C generates a SIGTERM signal. SIGTERM for terminate, unlike SIGKILL, can be either blocked or handled. One process also can signal another, thereby making signals an IPC mechanism.
Consider how a multi-processing application such as the Nginx web server might be shut down gracefully from another process. The kill function:
int kill(pid_t pid, int signum); /* declaration */can be used by one process to terminate another process or group of processes. If the first argument to function kill is greater than zero, this argument is treated as the pid (process ID) of the targeted process; if the argument is zero, the argument identifies the group of processes to which the signal sender belongs.
The second argument to kill is either a standard signal number (e.g., SIGTERM or SIGKILL) or 0, which makes the call to signal a query about whether the pid in the first argument is indeed valid. The graceful shutdown of a multi-processing application thus could be accomplished by sending a terminate signal—a call to the kill function with SIGTERM as the second argument—to the group of processes that make up the application. (The Nginx master process could terminate the worker processes with a call to kill and then exit itself.) The kill function, like so many library functions, houses power and flexibility in a simple invocation syntax.
Example 3. The graceful shutdown of a multi-processing system
#include <stdio.h>
#include <signal.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
void graceful(int signum) {
printf("\tChild confirming received signal: %i\n", signum);
puts("\tChild about to terminate gracefully...");
sleep(1);
puts("\tChild terminating now...");
_exit(0); /* fast-track notification of parent */
}
void set_handler() {
struct sigaction current;
sigemptyset(¤t.sa_mask); /* clear the signal set */
current.sa_flags = 0; /* enables setting sa_handler, not sa_action */
current.sa_handler = graceful; /* specify a handler */
sigaction(SIGTERM, ¤t, NULL); /* register the handler */
}
void child_code() {
set_handler();
while (1) { /** loop until interrupted **/
sleep(1);
puts("\tChild just woke up, but going back to sleep.");
}
}
void parent_code(pid_t cpid) {
puts("Parent sleeping for a time...");
sleep(5);
/* Try to terminate child. */
if (-1 == kill(cpid, SIGTERM)) {
perror("kill");
exit(-1);
}
wait(NULL); /** wait for child to terminate **/
puts("My child terminated, about to exit myself...");
}
int main() {
pid_t pid = fork();
if (pid < 0) {
perror("fork");
return -1; /* error */
}
if (0 == pid)
child_code();
else
parent_code(pid);
return 0; /* normal */
}
The shutdown program above simulates the graceful shutdown of a multi-processing system, in this case, a simple one consisting of a parent process and a single child process. The simulation works as follows:
- The parent process tries to fork a child. If the fork succeeds, each process executes its own code: the child executes the function child_code, and the parent executes the function parent_code.
- The child process goes into a potentially infinite loop in which the child sleeps for a second, prints a message, goes back to sleep, and so on. It is precisely a SIGTERM signal from the parent that causes the child to execute the signal-handling callback function graceful. The signal thus breaks the child process out of its loop and sets up the graceful termination of both the child and the parent. The child prints a message before terminating.
- The parent process, after forking the child, sleeps for five seconds so that the child can execute for a while; of course, the child mostly sleeps in this simulation. The parent then calls the kill function with SIGTERM as the second argument, waits for the child to terminate, and then exits.
Here is the output from a sample run:
% ./shutdown
Parent sleeping for a time...
Child just woke up, but going back to sleep.
Child just woke up, but going back to sleep.
Child just woke up, but going back to sleep.
Child just woke up, but going back to sleep.
Child confirming received signal: 15 ## SIGTERM is 15
Child about to terminate gracefully...
Child terminating now...
My child terminated, about to exit myself...
For the signal handling, the example uses the sigaction library function (POSIX recommended) rather than the legacy signal function, which has portability issues. Here are the code segments of chief interest:
- If the call to fork succeeds, the parent executes the parent_code function and the child executes the child_code function. The parent waits for five seconds before signaling the child:
If the kill call succeeds, the parent does a wait on the child's termination to prevent the child from becoming a permanent zombie; after the wait, the parent exits.
- The child_code function first calls set_handler and then goes into its potentially infinite sleeping loop. Here is the set_handler function for review:void set_handler() {
struct sigaction current; /* current setup */
sigemptyset(¤t.sa_mask); /* clear the signal set */
current.sa_flags = 0; /* for setting sa_handler, not sa_action */
current.sa_handler = graceful; /* specify a handler */
sigaction(SIGTERM, ¤t, NULL); /* register the handler */
}The first three lines are preparation. The fourth statement sets the handler to the function graceful, which prints some messages before calling _exit to terminate. The fifth and last statement then registers the handler with the system through the call to sigaction. The first argument to sigaction is SIGTERM for terminate, the second is the current sigaction setup, and the last argument (NULL in this case) can be used to save a previous sigaction setup, perhaps for later use.
Using signals for IPC is indeed a minimalist approach, but a tried-and-true one at that. IPC through signals clearly belongs in the IPC toolbox.
7. Thread synchronization :
https://hpc-tutorials.llnl.gov/posix/
https://www.cs.cmu.edu/afs/cs/academic/class/15492-f07/www/pthreads.html
Creating Threads:
Initially, your main() program comprises a single, default thread. All other threads must be explicitly created by the programmer. pthread_create creates a new thread and makes it executable. This routine can be called any number of times from anywhere within your code.
pthread_create arguments:
- thread: An opaque, unique identifier for the new thread returned by the subroutine.
- attr: An opaque attribute object that may be used to set thread attributes. You can specify a thread attributes object, or NULL for the default values.
- start_routine: the C routine that the thread will execute once it is created.
- arg: A single argument that may be passed to start_routine. It must be passed by reference as a pointer cast of type void. NULL may be used if no argument is to be passed.
The maximum number of threads that may be created by a process is implementation dependent. Programs that attempt to exceed the limit can fail or produce wrong results.
Querying and setting your implementation’s thread limit - Linux example shown. Demonstrates querying the default (soft) limits and then setting the maximum number of processes (including threads) to the hard limit. Then verifying that the limit has been overridden.
bash / ksh / sh example
$ ulimit -a
core file size (blocks, -c) 16
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 255956
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) unlimited
cpu time (seconds, -t) unlimited
max user processes (-u) 1024
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
$ ulimit -Hu
7168
$ ulimit -u 7168
$ ulimit -a
core file size (blocks, -c) 16
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 255956
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) unlimited
cpu time (seconds, -t) unlimited
max user processes (-u) 7168
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
tcsh/csh example
% limit
cputime unlimited
filesize unlimited
datasize unlimited
stacksize unlimited
coredumpsize 16 kbytes
memoryuse unlimited
vmemoryuse unlimited
descriptors 1024
memorylocked 64 kbytes
maxproc 1024
% limit maxproc unlimited
% limit
cputime unlimited
filesize unlimited
datasize unlimited
stacksize unlimited
coredumpsize 16 kbytes
memoryuse unlimited
vmemoryuse unlimited
descriptors 1024
memorylocked 64 kbytes
maxproc 7168
Once created, threads are peers, and may create other threads. There is no implied hierarchy or dependency between threads.
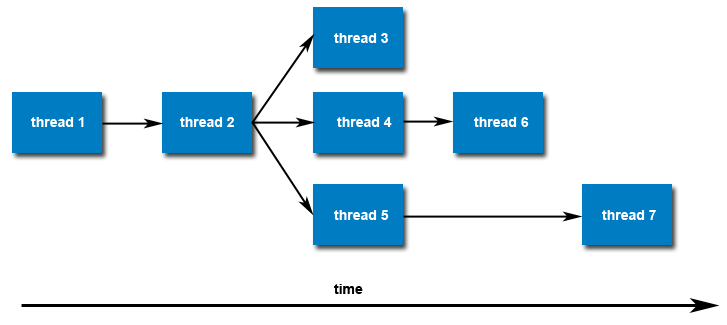
Thread Attributes:
By default, a thread is created with certain attributes. Some of these attributes can be changed by the programmer via the thread attribute object.
pthread_attr_init and pthread_attr_destroy are used to initialize/destroy the thread attribute object.
Other routines are then used to query/set specific attributes in the thread attribute object. Attributes include:
- Detached or joinable state
- Scheduling inheritance
- Scheduling policy
- Scheduling parameters
- Scheduling contention scope
- Stack size
- Stack address
- Stack guard (overflow) size
- Some of these attributes will be discussed later.
Thread Binding and Scheduling:
Question: After a thread has been created, how do you know a) when it will be scheduled to run by the operating system, and b) which processor/core it will run on?
Click for answer
The Pthreads API provides several routines that may be used to specify how threads are scheduled for execution. For example, threads can be scheduled to run FIFO (first-in first-out), RR (round-robin) or OTHER (operating system determines). It also provides the ability to set a thread’s scheduling priority value.
These topics are not covered here, however a good overview of “how things work” under Linux can be found in the sched_setscheduler man page.
The Pthreads API does not provide routines for binding threads to specific cpus/cores. However, local implementations may include this functionality - such as providing the non-standard pthread_setaffinity_np routine. Note that “_np” in the name stands for “non-portable”.
Also, the local operating system may provide a way to do this. For example, Linux provides the sched_setaffinity routine.
Terminating Threads & pthread_exit()
There are several ways in which a thread may be terminated:
- The thread returns normally from its starting routine. Its work is done.
- The thread makes a call to the
pthread_exitsubroutine - whether its work is done or not. - The thread is canceled by another thread via the
pthread_cancelroutine. - The entire process is terminated due to making a call to either the
exec()orexit() - If
main()finishes first, without callingpthread_exitexplicitly itself
The pthread_exit() routine allows the programmer to specify an optional termination status parameter. This optional parameter is typically returned to threads “joining” the terminated thread (covered later).
In subroutines that execute to completion normally, you can often dispense with calling pthread_exit() - unless, of course, you want to pass the optional status code back.
Cleanup: the pthread_exit() routine does not close files; any files opened inside the thread will remain open after the thread is terminated.
Discussion on calling pthread_exit() from main():
There is a definite problem if
main()finishes before the threads it spawned if you don’t callpthread_exit()explicitly. All of the threads it created will terminate becausemain()is done and no longer exists to support the threads.By having
main()explicitly callpthread_exit()as the last thing it does,main()will block and be kept alive to support the threads it created until they are done.
Example: Pthread Creation and Termination
This simple example code creates 5 threads with the pthread_create() routine. Each thread prints a “Hello World!” message, and then terminates with a call to pthread_exit().
#include <pthread.h>
#include <stdio.h>
#define NUM_THREADS 5
void *PrintHello(void *threadid)
{
long tid;
tid = (long)threadid;
printf("Hello World! It's me, thread #%ld!\n", tid);
pthread_exit(NULL);
}
int main (int argc, char *argv[])
{
pthread_t threads[NUM_THREADS];
int rc;
long t;
for(t=0; t<NUM_THREADS; t++){
printf("In main: creating thread %ld\n", t);
rc = pthread_create(&threads[t], NULL, PrintHello, (void *)t);
if (rc){
printf("ERROR; return code from pthread_create() is %d\n", rc);
exit(-1);
}
}
/* Last thing that main() should do */
pthread_exit(NULL);
}
Output:
In main: creating thread 0
In main: creating thread 1
Hello World! It's me, thread #0!
In main: creating thread 2
Hello World! It's me, thread #1!
Hello World! It's me, thread #2!
In main: creating thread 3
In main: creating thread 4
Hello World! It's me, thread #3!
Hello World! It's me, thread #4!8. subnetting:
https://www.techopedia.com/6/28587/internet/8-steps-to-understanding-ip-subnetting (best ***)
https://youtu.be/POPoAjWFkGg (or) https://tkssharma-devops.gitbook.io/devops-training/basic-networking/internet-protocol/cidr-and-subnetting
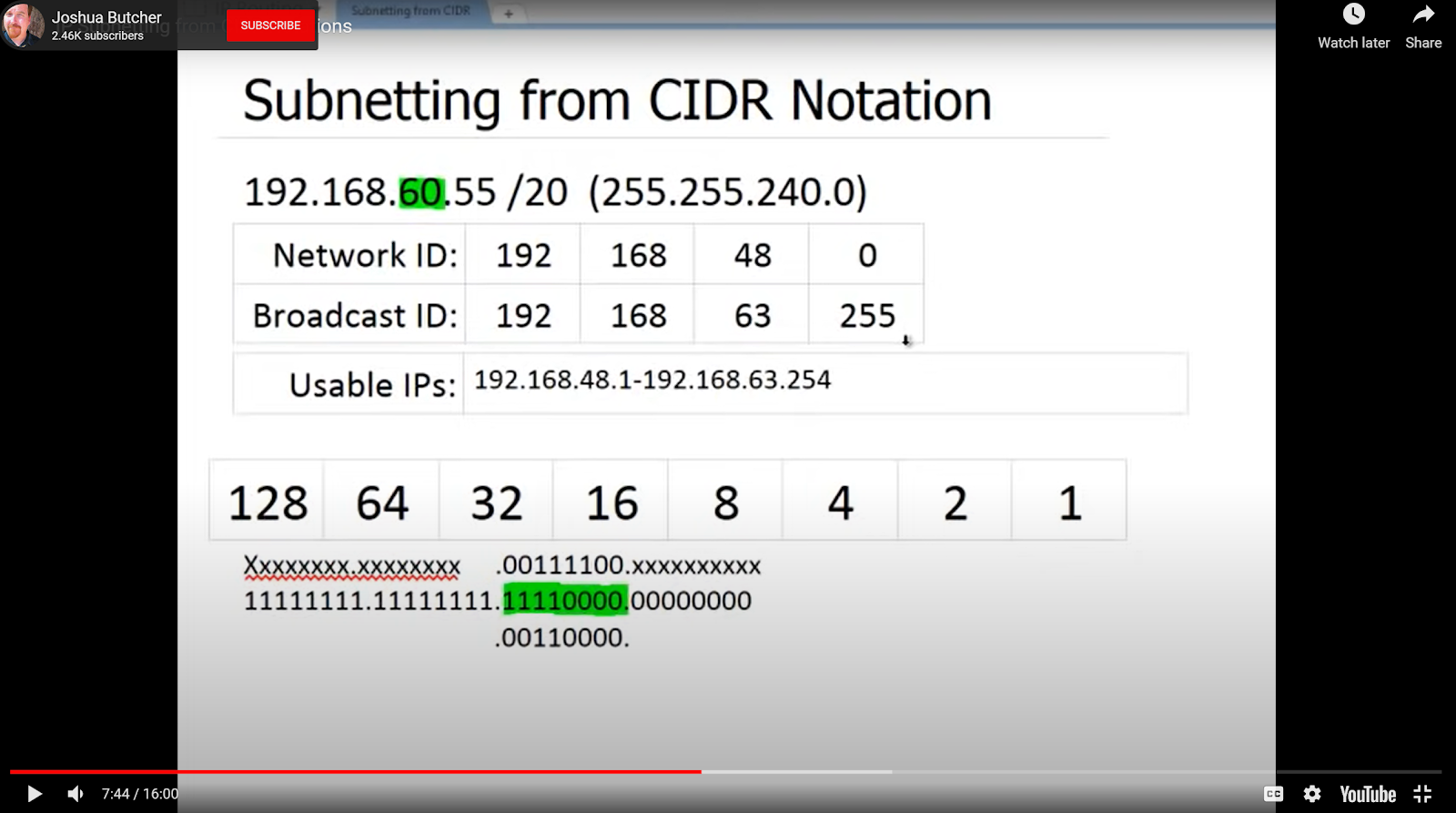
calculator:

https://www.site24x7.com/tools/ipv4-subnetcalculator.html
https://jodies.de/ipcalc?host=192.168.60.55&mask1=20&mask2=
9. Variable Length Subnet Mask (VLSM)
Ref: https://www.techtarget.com/searchnetworking/definition/variable-length-subnet-maskImplementing a VLSM subnet
In VLSM, each subnet chooses the block size based on its requirement. So, if requirements change, subnetting will be required multiple times.
In an organization with multiple departments, different departments may require a different number of IP addresses and subnets (some more and some less). To subnet the subnets in a way that minimizes IP address wastage, VLSM is preferable to FLSM.
Suppose the available IP address block is 192.168.1.0/24, and the requirement is to create four subnets for four departments:
Subnet A: 120 hosts
Subnet B: 50 hosts
Subnet C: 26 hosts
Subnet D: 2 hosts
Here are the steps to allocate the IPs for departments using VLSM:
- Select the block size for each segment. This must be greater than or at least equal to the sum of the host addresses, broadcast addresses and network addresses.
- List all possible subnets:
- Keeping the block size in mind, arrange all the segments in descending order, i.e., list the highest first, then the second highest, and so on, all the way down to the subnet with the lowest requirement. For this example, the order would be:
i. Subnet A: 120 hosts
ii. Subnet B: 50 hosts
iii. Subnet C: 26 hosts
iv. Subnet D: 2 hosts- Assign the appropriate subnet mask to each subnet. Identify the highest IP available and allocate it to the highest requirement. So, here, 192.168.1.0/25 has 126 valid IP addresses that can be assigned to the 120 hosts required by Subnet A.
- For the next segment, an IP is required that can handle 50 hosts. The IP subnet mask /26 is the next highest in the list. It can accommodate 64 hosts, so it should be assigned to the 50-host requirement of Subnet B.
- Similarly, the requirements of Subnet C can be fulfilled by the next IP subnet /27 because it has 32 valid host IPs that can accommodate the 26 hosts required by this subnet.
- Finally, for the two IP addresses required by Subnet D, the subnet /29 can be selected. Because the block size of the subnet mask must be greater than or equal to the sum of the host addresses, broadcast addresses and network addresses, the subnet mask /30 with only two hosts should not be selected.
Using VLSM
To use VLSM, a network administrator must use a routing protocol that supports it, such as:


- Routing Information Protocol v2 (RIPv2)
- Open Shortest Path First (OSPF)
- Intermediate System-to-Intermediate System (IS-IS)
- Border Gateway Protocol (BGP)
- Enhanced Interior Gateway Routing Protocol (EIGRP)
Classful routing protocols like RIPv1 and IGRP do not support VLSM, so before configuring the router for VLSM, network engineers must check whether the protocol supports VLSM
VLSM is similar in concept and intent to Classless Inter-Domain Routing (CIDR), which allows a single internet domain to have an address space that does not fit into traditional address classes. VLSM was originally defined in IETF RFC 1812.
10. RIP vs OSPFhttps://www.geeksforgeeks.org/difference-between-rip-and-ospf/
1. Routing Information Protocol (RIP):
RIP stands for Routing Information Protocol in which distance vector routing protocol is used for data/packet transmission. In the Routing Information Protocol (RIP), the maximum number of Hop is 15, because it prevents routing loops from source to destination. Mechanisms like the split horizon, route poisoning, and hold down are used to prevent from incorrect or wrong routing information. Sally Floyd and Van Jacobson [1994] suggest that, without slight randomization of the timer, the timers are synchronized over time. Compared to other routing protocols, RIP (Routing Information Protocol) is poor and limited in size i.e. small network. The main advantage of using RIP is it uses the UDP (User Datagram Protocol).
2. Open Shortest Path First (OSPF):
OSPF stands for Open Shortest Path First which uses a link-state routing algorithm. Using the link state information which is available in routers, it constructs the topology in which topology determines the routing table for routing decisions. It supports both variable-length subnet masking and classless inter-domain routing addressing models. Since it uses Dijkstra’s algorithm, it computes the shortest path tree for each route. The main advantage of the OSPF (Open Shortest Path first) is that it handles the error detection by itself and it uses multicast addressing for routing in a broadcast domain.
Difference Between RIP and OSPF
SR.NO RIP OSPF 1 RIP Stands for Routing Information Protocol. OSPF stands for Open Shortest Path First. 2 RIP works on the Bellman-Ford algorithm. OSPF works on Dijkstra algorithm. 3 It is a Distance Vector protocol and it uses the distance or hops count to determine the transmission path. It is a link-state protocol and it analyzes different sources like the speed, cost and path congestion while identifying the shortest path. 4 It is used for smaller size organizations. It is used for larger size organizations in the network. 5 It allows a maximum of 15 hops. There is no such restriction on the hop count. 6 It is not a more intelligent dynamic routing protocol. It is a more intelligent routing protocol than RIP. 7 The networks are classified as areas and tables here. The networks are classified as areas, sub-areas, autonomous systems, and backbone areas here. 8 Its administrative distance is 120. Its administrative distance is 110. 9 RIP uses UDP(User Datagram Protocol) Protocol. OSPF works for IP(Internet Protocol) Protocol. 10 It calculates the metric in terms of Hop Count. It calculates the metric in terms of bandwidth. 11 In RIP, the whole routing table is to be broadcasted to the neighbors every 30 seconds by the routers. In OSPF, parts of the routing table are only sent when a change has been made to it. 12 RIP utilizes less memory compared to OSPF but is CPU intensive like OSPF. OSPF device resource requirements are CPU intensive and memory. 13 It consumes more bandwidth because of greater network resource requirements in sending the whole routing table. It consumes less bandwidth as only part of the routing table is to send. 14 Its multicast address is 224.0.0.9. OSPF’s multicast addresses are 224.0.0.5 and 224.0.0.6.
Route poisoning occurs when a RIP device learns that a route to a destination has failed. When this happens RIP will advertise the failed destination out ALL of its interfaces with a metric of 16 (which is considered unreachable); this tells all of its neighbors that it no longer has a route to that specific network.